🌜|从零搭建网络| VisionTransformer系列网络详解及搭建🌛
文章目录
- 🌜|从零搭建网络| VisionTransformer系列网络详解及搭建🌛
- 🌜 前言 🌛
- 🌜 VIT模型详解 🌛
- 🌜 VIT模型架构 🌛
- 🌜 Patch 🌛
- 🌜 Encoder Block 🌛
- 🌜 MLP Head 🌛
- 🌜 VIT模型复现 🌛
- 🌜 二维Patch Embedding的实现 🌛
- 🌜 二维Multi_head Attention(多头自注意力机制)的实现 🌛
- 🌜 二维Encoder Block的实现 🌛
- 🌜 二维VisionTransformer的实现 🌛
- 🌜 一维VisionTransformer的实现 🌛
- 🌜 总结 🌛
🌜 前言 🌛
最近学习的时候遇到了一点小小的瓶颈,导致停更了好长时间,最近突然想到能不能从大模型方面有个总体的改进,就想到最近比较火的VisionTransformer(VIT)模型,实验了一段时间之后确实有了很多想法,决定写一篇博客浅浅记录一下。
本篇博客主要介绍一维Transformer(1D_VIT)模型、二维Transformer(2D_VIT)模型网络的模型简介以及复现的相关细节。
🌜 VIT模型详解 🌛
VisionTransformer(VIT)模型最早在2020年发表的一篇论文上的文章:https://arxiv.org/abs/2010.11929,从论文名称An Image Worth 16x16 Words:Transformers For Image Recognition At Scale可以看出VIT模型不同于传统的Transformer模型主要运用于自然语言处理领域,他本身就是为了图像分类任务而设计,同时保留了Transformer模型中较为重要的Positional Encoding、Self-Attention以及Patch等操作,其独特的自注意力机制、全局的感受野以及并行处理能力使得VIT模型得以打破传统卷积神经网络(CNN)在视觉任务中的主导地位。

🌜 VIT模型架构 🌛
VIT模型整体采用了传统Transformer的结构,同时在某些地方做了更改。
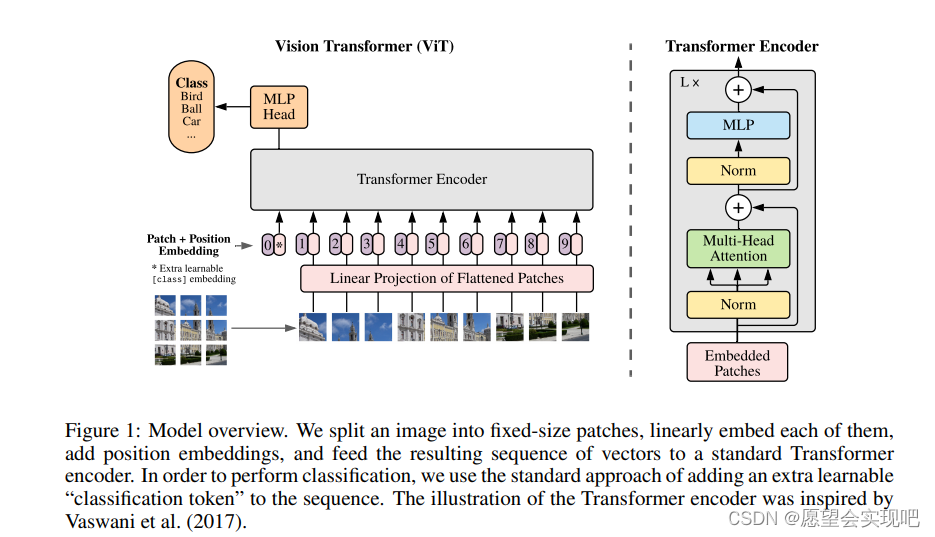
由于VIT模型整体用于图像的分类任务,所以在Embedding之前整体对于图片按照分辨率分成不同的Patch,并且在 MLP Head和Class Token中也做了相关改进,后续将分别从Patch、Attention、Encoder和MLP 四个方面详细介绍VIT模型的架构。
🌜 Patch 🌛

上图是一个vit模型的简要工作图。其次介绍一下Patch Embedding的过程,假如输入数据为三通道的彩色RGB图像,并且每张图像像素为224×224。首先将每张图像分成大小相同的token,假设分成大小为16×16的token,则一共可以分成14×14个大小相同的token。分成每个信息互不相交的token之后,会将其进行一个线性的恒等映射。
这种线性的恒等映射一般为一个线性层,从而将数据映射到更高维的空间,这个过程可以看做一种嵌入(embedding)。该线性层的作用是将展平后的图像块转换为固定维度的特征向量,是的每个图像块在Transformer中作为一个token处理。
并且在这个过程中恒等映射可以起到保持原始特征的作用。
因此在进行embedding之后,数据的形状就会变为[num_token,dim_token],在上述例子中就会变成[196,embed_dim],这里的embed_dim是我们自己所设置的token嵌入维度。另外就是在patch embed之后,vit模型会在token中嵌入一个class token用于后续分类层的分类任务,而class token的形状是有patch后token的大小所决定。如上例子所示,当数据经过embedding变为[196,embed_dim]之后,会拼接一个大小为[1,embed_dim]的class token,最后就是注意这里的是方式是cat拼接在一起,而不是单纯的相加,在进行拼接后,数据会变为[197,embed_dim]。
进行完class token的拼接后会需要加上position token,这里position token的相加和正常transformer中position token的相加类似,求得每个token位置的余弦相似度后生成进行相加,但是和class token的拼接不同的地方是,这里的相加只会改变token大小,并不会对token的维度产生任何影响,所以继续回到刚才的例子,生成[197,embed_dim]的position token,相加后数据形状还是[197,embed_dim]。
🌜 Encoder Block 🌛
Encoder block是vit模型的核心组件之一,其中单个编码器的结构和传统的Transformer模型的编码器非常相似,主要由多头注意力机制(Multi-Head Self-Attention)、残差连接与层归一化(Residual Connection and Layer Normalization)、前馈神经网络(Feed-Forward Neural Network,FFN) 所组成。下图为Encoder block的结构图。
将token首先进行归一化处理后使用多头注意力机制来在全局范围内捕捉不同token之间的依赖关系,而不仅限于局部感受野,这对于理解图像中的复杂结构和长距离依赖关系很重要,同时通过并行处理多个注意力头,可以很好地增强模型的表示能力和学习能力;而后使用残差连接将输入值与多头注意力的输出值相加一方面缓解深度网络中梯度消失或爆炸的问题,确保梯度在反向传播中更稳定地流动,并且某种程度上加速模型收敛速度;最后在经过层归一化、全连接层以及残差连接,在全连接层中引入了非线性激活函数,使得模型能够学习到更多的非线性特征,从而进一步提升其表征能力。vit 模型正是通过将这种Encoder block重复堆叠L次来完成token的Encoder。
🌜 MLP Head 🌛
上述模块就是VIT模型提取特征最为重要的几个模块,而MLP Head多数情况下都只是用来做一个分类处理,下面为详细的结构图。(图片来自B站UP主@霹雳吧啦Wz ,感谢大佬)

可以从中看出主要就是由线性层、激活函数以及Drop out层所组成。
🌜 VIT模型复现 🌛
由于我的课题是关于一维信号分类,所以我在复现模型的时候会多复现一个可以处理一维信号的一维模型,所以本节VIT模型的实现包括VIT_1D(一维VIT)和VIT_2D(二维VIT)的实现。并且由于VIT模型中一维和二维的实现差别不太大,所以后面在介绍的时候着重介绍二维VIT模型的实现,一维VIT模型会在本节末尾给出。其中VIT模型的实现主要包括Patch Embedding层的实现、Multi_head Attention(多头自注意力机制)的实现、Encoder block的实现以及最后MLP Head的实现。
🌜 二维Patch Embedding的实现 🌛
本节代码实现部分默认输入数据为3通道224×224大小的RGB图像,并且patch_size(token大小)为16×16,embed_dim(嵌入后的数据维度)为768。即以下是Patch Embedding的初始化部分。
class PatchEmbed(torch.nn.Module):
def __init__(self,img_size = 224,patch_size = 16,in_channel = 3,embed_dim = 768,norm_layer = None):
'''
初始化
:param img_size: 输入数据大小
:param patch_size: 分成的token大小
:param in_channel: 输入数据通道数
:param embed_dim: embed后的维度大小
:param norm_layer: 是否使用归一化处理
'''
super().__init__()
img_size = (img_size,img_size)
patch_size = (patch_size,patch_size)
self.image_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0],img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = torch.nn.Conv2d(in_channel,embed_dim,patch_size,patch_size[0])
self.norm = norm_layer(embed_dim) if norm_layer else torch.nn.Identity()
由于VIT模型进行embedding的重要手段为使用卷积层进行维度映射,所以这里实例化一个卷积核大小为patch_size×patch_size的卷积层,并且设置输出维度为embed_dim,并且最后在初始化归一化层时,令如果有输入归一化层就是用输入的归一化层,否则不适用归一化措施。
下面是前向传播的代码:
def forward(self,x):
# B,C,H,W = x.shape
x = self.proj(x).flatten(2).transpose(1,2)#[B,C,HW] [B,HW,C] [B,token,dim]
x = self.norm(x)
return x
假设输入数据x的初始形状为[B,C,H,W]。从代码中可以看到,输入数据首先是经过初始化中定义的卷积层。此时数据形状为[B,embed_dim,H_patch,W_patch];而后使用flatten(2)将数据从切片为2的地方开始进行展平操作,即对数据后两个维度展平,展平后的数据形状为[B,embed_dim,H_patch×W_patch];最后使用transpose(1,2)将数据切片的第1个维度和第2个维度进行位置的互换。最后数据形状变为:[B,H_patch×W_patch,embed_dim],并且此时第1个维度为num_token,第二个维度为token_dim。transpose函数的主要作用就是改变数据维度位置,下面是一段实例代码,更清晰展示transpose函数的作用。
import torch
x = torch.randn(1,3,2)
print(x.shape)#torch.size([1,3,2])
x = x.transpose(1,2)
print(x.shape)#torch.size([1,2,3])
Patch Embedding完整代码为:
class PatchEmbed(torch.nn.Module):
def __init__(self,img_size = 224,patch_size = 16,in_channel = 3,embed_dim = 768,norm_layer = None):
'''
初始化
:param img_size: 输入数据大小
:param patch_size: 分成的token大小
:param in_channel: 输入数据通道数
:param embed_dim: embed后的维度大小
:param norm_layer: 是否使用归一化处理
'''
super().__init__()
img_size = (img_size,img_size)
patch_size = (patch_size,patch_size)
self.image_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0],img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = torch.nn.Conv2d(in_channel,embed_dim,patch_size,patch_size[0])
self.norm = norm_layer(embed_dim) if norm_layer else torch.nn.Identity()
def forward(self,x):
# B,C,H,W = x.shape
x = self.proj(x).flatten(2).transpose(1,2)#[B,C,HW] [B,HW,C] [B,token,dim]
x = self.norm(x)
return x
🌜 二维Multi_head Attention(多头自注意力机制)的实现 🌛
首先附上自注意力机制的实现公式:

多头自注意力机制的实现就不进行过多赘述了,就是分别寻找q,k,v向量使其分别进行信息交互,与正常多头自注意力机制不一样的地方是这里实现的时候加入了Dropout层,并且在输入参数的地方可以自主输入缩放因子的数值。
多头自注意力机制实现代码:
class Multihead_Attention(torch.nn.Module):
def __init__(self,
dim, #输入token的dimension
num_heads = 8,#head数量
qkv_bias = False,#生成QKV时是否使用偏置
qk_scale = None,#自定义缩放因子
attn_drop_ratio = 0.,
proj_drop_ratio = 0.):
'''
多头自注意力机制
:param dim: 输入token的维度
:param num_heads: 注意力头的数量
:param qkv_bias: 生成三个向量时是否使用偏置
:param qk_scale: 是否自定义缩放因子
:param attn_drop_ratio: 注意力机制层Dropout的概率
:param proj_drop_ratio: 映射层Dropout的概率
'''
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads#每一个head的dimension
self.scale = qk_scale or head_dim ** -0.5
self.qkv = torch.nn.Linear(dim,dim*3,bias=qkv_bias)
self.attn_drop = torch.nn.Dropout(attn_drop_ratio)
self.proj = torch.nn.Linear(dim,dim)
self.proj_drop = torch.nn.Dropout(proj_drop_ratio)
def forward(self,x):
B,N,C = x.shape
qkv = self.qkv(x).reshape(B,N,3,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
q,k,v = qkv[0],qkv[1],qkv[2]
attn = (q @ k.transpose(-2,-1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1,2).reshape(B,N,C)
x = self.proj(x)
x = self.proj_drop(x)
return x
这里生成三个向量的时候,并没有选择一个一个生成,而是一次性生成三个然后在分别拿出来进行信息交互处理。
🌜 二维Encoder Block的实现 🌛

上图为Encoder block的结构,直接根据上述结构进行搭建即可。下面为搭建代码:
class Block(torch.nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio = 4.,
qkv_bias = False,
qk_scale = None,
drop_ratio = 0,
attn_drop_ratio = 0.,
drop_path_ratio = 0.,
act_layer = torch.nn.GELU,
norm_layer = torch.nn.LayerNorm):
'''
Encoder block
:param dim: token 的输入维度
:param num_heads: 注意力头的数量
:param mlp_ratio: mlp隐藏层层倍数
:param qkv_bias: qkv是否使用偏置
:param qk_scale: 是否自定义缩放因子
:param drop_ratio: 映射层dropout概率
:param attn_drop_ratio: 注意力机制dropout概率
:param drop_path_ratio: 是否使用Droppath
:param act_layer: 是否自定义激活函数
:param norm_layer: 是否自定义归一化层
'''
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Multihead_Attention(dim,num_heads,qkv_bias,qk_scale,attn_drop_ratio,drop_ratio)
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else torch.nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim,hidden_features=mlp_hidden_dim,act_layer=act_layer,drop_ratio=drop_ratio)
def forward(self,x):
x += self.drop_path(self.attn(self.norm1(x)))
x += self.drop_path(self.mlp(self.norm2(x)))
return x
🌜 二维VisionTransformer的实现 🌛

上图为VisionTransformer的总体结构,在初始化的过程中要记得把class token和position token也一并进行初始化,下面为初始化部分代码:
class VisionTransformer(torch.nn.Module):
def __init__(self,img_size = 224, #输入图片大小
patch_size = 16, #每个token大小
in_channel = 3, #输入图片通道
num_classes = 1000, #类别
embed_dim = 768, #token维度
depth = 12, #encoder重复次数
num_heads = 12, #多头注意力机制
mlp_ratio = 4.0,#mlp隐藏层倍数
qkv_bias = True, #查询QKV时是否使用偏置
qk_scale = None, #自定义缩放因子
representation_size = None, #是否使用representation
distilled = False, #是否知识蒸馏
drop_ratio = 0, #dropout比例
attn_drop_ratio = 0, #attention中dropout比例
drop_path_ratio = 0, #encoder中dropout比例
embed_layer = PatchEmbed, #patchembed
norm_layer = None, #归一化
act_layer = None #激活函数
):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.num_tokens = 2 if distilled else 1 #num_token默认为1
norm_layer = norm_layer or partial(torch.nn.LayerNorm,eps = 1e-6)#默认为layernorm
act_layer = act_layer or torch.nn.GELU #激活函数默认为gelu
self.patch_embed = embed_layer(img_size,patch_size,in_channel,embed_dim,norm_layer)
num_patches = self.patch_embed.num_patches
self.cls_token = torch.nn.Parameter(torch.zeros(1,1,embed_dim)) #可训练参数(batch,1,embed_dim)
self.dist_token = torch.nn.Parameter(torch.zeros(1,1,embed_dim)) if distilled else None #知识蒸馏
self.pos_embed = torch.nn.Parameter(torch.zeros(1,num_patches+self.num_tokens,embed_dim))#(batch,197,768)
self.pos_drop = torch.nn.Dropout(p=drop_ratio)#position后的Dropout
dpr = [x.item() for x in torch.linspace(0,drop_path_ratio,depth)]#创建depth个递增的dpr
self.blocks = torch.nn.Sequential(*[
Block(embed_dim,num_heads,mlp_ratio,qkv_bias,qk_scale,drop_ratio,attn_drop_ratio,dpr[i],norm_layer=norm_layer,act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
#representation layer
if representation_size and not distilled:#是否使用representation
self.has_logits = True
self.num_features = representation_size
self.pre_logits = torch.nn.Sequential(OrderedDict([
('fc',torch.nn.Linear(embed_dim,representation_size)),
('act',torch.nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = torch.nn.Identity()
#classifier heads
self.head = torch.nn.Linear(self.num_features,num_classes) if num_classes > 0 else torch.nn.Identity()#linear
self.head_dist = None
if distilled:
self.head_dist = torch.nn.Linear(self.embed_dim,self.num_classes) if num_classes > 0 else torch.nn.Identity()
#weight init
torch.nn.init.trunc_normal_(self.pos_embed,std=0.02)
if self.dist_token is not None:
torch.nn.init.trunc_normal_(self.dist_token,std=0.02)
torch.nn.init.trunc_normal_(self.cls_token,std = 0.02)
self.apply(_init_vit_weights)
在传入的参数中有一个representation_size指的是是否使用representation。如果使用的话在最后的MLP Head中会加入一个卷积层和一个Tanh激活函数,在源码中预训练阶段使用了representation,而在迁移学习之后没有使用,后续使用的话我们可以根据自己的 需求来看是否使用。还有一个就是distilled指的是是否使用知识蒸馏,没有这方面需求的话可以直接将其设置为False。
初始化结束后,会先进行一个特征提取的前向传播,下面是实现代码:
def forward_features(self,x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0],-1,-1)
if self.dist_token is None:
x = torch.cat((cls_token,x),dim=1)
else:
x = torch.cat((cls_token,self.dist_token.expand(x.shape[0],-1,-1),x),dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:,0])
else:
return x[:,0],x[:,1]
这里比较需要注意class token是使用cat拼接上去的,而position token是直接进行相加。
最后是整体的前向传播代码:
def forward(self,x):
x = self.forward_features(x)
if self.head_dist is not None:
x,x_dist = self.head(x[0]),self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
return x,x_dist
else:
return (x+x_dist) / 2
else:
x = self.head(x)
return x
不需要使用知识蒸馏的情况下,可以直接将参数distilled设置为False或者是将代码中相关内容直接删除。
二维VisionTransformer完整实现代码:
import torch
from collections import OrderedDict
from functools import partial
#二维网络
def drop_path(x,drop_prob:float = 0.,training:bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape,dtype=x.dtype,device=x.device)
random_tensor.floor_()
output = x.div(keep_prob) * random_tensor
return output
class DropPath(torch.nn.Module):
def __init__(self,drop_prob = None):
super().__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path(x,self.drop_prob,self.training)
class PatchEmbed(torch.nn.Module):
def __init__(self,img_size = 224,patch_size = 16,in_channel = 3,embed_dim = 768,norm_layer = None):
'''
初始化
:param img_size: 输入数据大小
:param patch_size: 分成的token大小
:param in_channel: 输入数据通道数
:param embed_dim: embed后的维度大小
:param norm_layer: 是否使用归一化处理
'''
super().__init__()
img_size = (img_size,img_size)
patch_size = (patch_size,patch_size)
self.image_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0],img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = torch.nn.Conv2d(in_channel,embed_dim,patch_size,patch_size[0])
self.norm = norm_layer(embed_dim) if norm_layer else torch.nn.Identity()
def forward(self,x):
# B,C,H,W = x.shape
x = self.proj(x).flatten(2).transpose(1,2)#[B,C,HW] [B,HW,C] [B,token,dim]
x = self.norm(x)
return x
class Multihead_Attention(torch.nn.Module):
def __init__(self,
dim, #输入token的dimension
num_heads = 8,#head数量
qkv_bias = False,#生成QKV时是否使用偏置
qk_scale = None,#自定义缩放因子
attn_drop_ratio = 0.,
proj_drop_ratio = 0.):
'''
多头自注意力机制
:param dim: 输入token的维度
:param num_heads: 注意力头的数量
:param qkv_bias: 生成三个向量时是否使用偏置
:param qk_scale: 是否自定义缩放因子
:param attn_drop_ratio: 注意力机制层Dropout的概率
:param proj_drop_ratio: 映射层Dropout的概率
'''
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads#每一个head的dimension
self.scale = qk_scale or head_dim ** -0.5
self.qkv = torch.nn.Linear(dim,dim*3,bias=qkv_bias)
self.attn_drop = torch.nn.Dropout(attn_drop_ratio)
self.proj = torch.nn.Linear(dim,dim)
self.proj_drop = torch.nn.Dropout(proj_drop_ratio)
def forward(self,x):
B,N,C = x.shape
qkv = self.qkv(x).reshape(B,N,3,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
q,k,v = qkv[0],qkv[1],qkv[2]
attn = (q @ k.transpose(-2,-1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1,2).reshape(B,N,C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class MLP(torch.nn.Module):
def __init__(self,in_features,
hidden_features = None,#一般为in_features的四倍
out_features = None,
act_layer = torch.nn.GELU,
drop_ratio = 0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = torch.nn.Linear(in_features,hidden_features)
self.act = act_layer()
self.fc2 = torch.nn.Linear(hidden_features,out_features)
self.drop = torch.nn.Dropout(drop_ratio)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(torch.nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio = 4.,
qkv_bias = False,
qk_scale = None,
drop_ratio = 0,
attn_drop_ratio = 0.,
drop_path_ratio = 0.,
act_layer = torch.nn.GELU,
norm_layer = torch.nn.LayerNorm):
'''
Encoder block
:param dim: token 的输入维度
:param num_heads: 注意力头的数量
:param mlp_ratio: mlp隐藏层层倍数
:param qkv_bias: qkv是否使用偏置
:param qk_scale: 是否自定义缩放因子
:param drop_ratio: 映射层dropout概率
:param attn_drop_ratio: 注意力机制dropout概率
:param drop_path_ratio: 是否使用Droppath
:param act_layer: 是否自定义激活函数
:param norm_layer: 是否自定义归一化层
'''
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Multihead_Attention(dim,num_heads,qkv_bias,qk_scale,attn_drop_ratio,drop_ratio)
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else torch.nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim,hidden_features=mlp_hidden_dim,act_layer=act_layer,drop_ratio=drop_ratio)
def forward(self,x):
x += self.drop_path(self.attn(self.norm1(x)))
x += self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(torch.nn.Module):
def __init__(self,img_size = 224, #输入图片大小
patch_size = 16, #每个token大小
in_channel = 3, #输入图片通道
num_classes = 1000, #类别
embed_dim = 768, #token维度
depth = 12, #encoder重复次数
num_heads = 12, #多头注意力机制
mlp_ratio = 4.0,#mlp隐藏层倍数
qkv_bias = True, #查询QKV时是否使用偏置
qk_scale = None, #自定义缩放因子
representation_size = None, #是否使用representation
distilled = False, #是否知识蒸馏
drop_ratio = 0, #dropout比例
attn_drop_ratio = 0, #attention中dropout比例
drop_path_ratio = 0, #encoder中dropout比例
embed_layer = PatchEmbed, #patchembed
norm_layer = None, #归一化
act_layer = None #激活函数
):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.num_tokens = 2 if distilled else 1 #num_token默认为1
norm_layer = norm_layer or partial(torch.nn.LayerNorm,eps = 1e-6)#默认为layernorm
act_layer = act_layer or torch.nn.GELU #激活函数默认为gelu
self.patch_embed = embed_layer(img_size,patch_size,in_channel,embed_dim,norm_layer)
num_patches = self.patch_embed.num_patches
self.cls_token = torch.nn.Parameter(torch.zeros(1,1,embed_dim)) #可训练参数(batch,1,embed_dim)
self.dist_token = torch.nn.Parameter(torch.zeros(1,1,embed_dim)) if distilled else None #知识蒸馏
self.pos_embed = torch.nn.Parameter(torch.zeros(1,num_patches+self.num_tokens,embed_dim))#(batch,197,768)
self.pos_drop = torch.nn.Dropout(p=drop_ratio)#position后的Dropout
dpr = [x.item() for x in torch.linspace(0,drop_path_ratio,depth)]#创建depth个递增的dpr
self.blocks = torch.nn.Sequential(*[
Block(embed_dim,num_heads,mlp_ratio,qkv_bias,qk_scale,drop_ratio,attn_drop_ratio,dpr[i],norm_layer=norm_layer,act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
#representation layer
if representation_size and not distilled:#是否使用representation
self.has_logits = True
self.num_features = representation_size
self.pre_logits = torch.nn.Sequential(OrderedDict([
('fc',torch.nn.Linear(embed_dim,representation_size)),
('act',torch.nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = torch.nn.Identity()
#classifier heads
self.head = torch.nn.Linear(self.num_features,num_classes) if num_classes > 0 else torch.nn.Identity()#linear
self.head_dist = None
if distilled:
self.head_dist = torch.nn.Linear(self.embed_dim,self.num_classes) if num_classes > 0 else torch.nn.Identity()
#weight init
torch.nn.init.trunc_normal_(self.pos_embed,std=0.02)
if self.dist_token is not None:
torch.nn.init.trunc_normal_(self.dist_token,std=0.02)
torch.nn.init.trunc_normal_(self.cls_token,std = 0.02)
self.apply(_init_vit_weights)
def forward_features(self,x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0],-1,-1)
if self.dist_token is None:
x = torch.cat((cls_token,x),dim=1)
else:
x = torch.cat((cls_token,self.dist_token.expand(x.shape[0],-1,-1),x),dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:,0])
else:
return x[:,0],x[:,1]
def forward(self,x):
x = self.forward_features(x)
if self.head_dist is not None:
x,x_dist = self.head(x[0]),self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
return x,x_dist
else:
return (x+x_dist) / 2
else:
x = self.head(x)
return x
def _init_vit_weights(m):
if isinstance(m,torch.nn.Linear):
torch.nn.init.trunc_normal_(m.weight,std=.01)
if m.bias is not None:
torch.nn.init.zeros_(m.bias)
elif isinstance(m,torch.nn.Conv2d):
torch.nn.init.kaiming_normal(m.weight,mode = 'fan_out')
if m.bias is not None:
torch.nn.init.zeros_(m.bias)
elif isinstance(m,torch.nn.LayerNorm):
torch.nn.init.zeros_(m.bias)
torch.nn.init.ones_(m.weight)
def vit_base_patch16_224(num_classes: int = 1000):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=None,
num_classes=num_classes)
return model
if __name__ == '__main__':
x = torch.randn(1,3,224,224)
model = vit_base_patch16_224(1000)
y = model(x)
print(y.shape)
print(model)
代码最后实例化了一个vit_base_patch16_224模型,其中需要预训练的权重可以根据连接下载自取。
🌜 一维VisionTransformer的实现 🌛
一维模型的实现主要是将代码中二维网络以及相关展平操作进行更改,下列是实现代码:
import torch
import os
from collections import OrderedDict
from functools import partial
#一维网络
def drop_path(x,drop_prob:float = 0.,training:bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape,dtype=x.dtype,device=x.device)
random_tensor.floor_()
output = x.div(keep_prob) * random_tensor
return output
class DropPath(torch.nn.Module):
def __init__(self,drop_prob = None):
super().__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path(x,self.drop_prob,self.training)
class PatchEmbed(torch.nn.Module):
def __init__(self,input_size,patch_size,in_channel,embed_dim,norm_layer = None):
super().__init__()
self.input_size = input_size
self.patch_size = patch_size
self.grid_size = input_size // patch_size
self.proj = torch.nn.Conv1d(in_channel,embed_dim,patch_size,patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else torch.nn.Identity()
def forward(self,x):
x = self.proj(x)
x = x.transpose(1,2)
x = self.norm(x)
return x
class Multihead_Attention(torch.nn.Module):
def __init__(self,
dim, #输入token的dimension
num_heads = 8,#head数量
qkv_bias = False,#生成QKV时是否使用偏置
qk_scale = None,#自定义缩放因子
attn_drop_ratio = 0,
proj_drop_ratio = 0):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads#每一个head的dimension
self.scale = qk_scale or head_dim ** -0.5
self.qkv = torch.nn.Linear(dim,dim*3,bias=qkv_bias)
self.attn_drop = torch.nn.Dropout(attn_drop_ratio)
self.proj = torch.nn.Linear(dim,dim)
self.proj_drop = torch.nn.Dropout(proj_drop_ratio)
def forward(self,x):
B,N,C = x.shape
# print(f'input shape:{x.shape}')
qkv = self.qkv(x)
# print(f'qkv shape:{qkv.shape}')
assert C % self.num_heads == 0, "Embedding dimension must be divisible by number of heads"
qkv = qkv.reshape(B, N, 3, self.num_heads, C // self.num_heads)
# print(f'reshape shape:{qkv.shape}')
qkv = qkv.permute(2, 0, 3, 1, 4)
q,k,v = qkv[0],qkv[1],qkv[2]
attn = (q @ k.transpose(-2,-1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1,2).reshape(B,N,C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class MLP(torch.nn.Module):
def __init__(self,in_features,
hidden_features = None,#一般为in_features的四倍
out_features = None,
act_layer = torch.nn.GELU,
drop_ratio = 0):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = torch.nn.Linear(in_features,hidden_features)
self.act = act_layer()
self.fc2 = torch.nn.Linear(hidden_features,out_features)
self.drop = torch.nn.Dropout(drop_ratio)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(torch.nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio = 4,
qkv_bias = False,
qk_scale = None,
drop_ratio = 0,
attn_drop_ratio = 0,
drop_path_ratio = 0,
act_layer = torch.nn.GELU,
norm_layer = torch.nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Multihead_Attention(dim,num_heads,qkv_bias,qk_scale,attn_drop_ratio,drop_ratio)
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0 else torch.nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim,hidden_features=mlp_hidden_dim,act_layer=act_layer,drop_ratio=drop_ratio)
def forward(self,x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(torch.nn.Module):
def __init__(self,img_size = 224, #输入数据大小
patch_size = 16, #每个token大小
in_channel = 3, #输入数据通道
num_classes = 1000, #类别
embed_dim = 768, #token维度
depth = 12, #encoder重复次数
num_heads = 12, #多头注意力机制
mlp_ratio = 4.0,#mlp隐藏层倍数
qkv_bias = True, #查询QKV时是否使用偏置
qk_scale = None, #自定义缩放因子
representation_size = None, #是否使用representation
distilled = False, #是否知识蒸馏
drop_ratio = 0., #dropout比例
attn_drop_ratio = 0., #attention中dropout比例
drop_path_ratio = 0., #encoder中dropout比例
embed_layer = PatchEmbed, #patchembed
norm_layer = None, #归一化
act_layer = None #激活函数
):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.num_tokens = 2 if distilled else 1 #num_token默认为1
norm_layer = norm_layer or partial(torch.nn.LayerNorm,eps = 1e-6)#默认为layernorm
act_layer = act_layer or torch.nn.GELU #激活函数默认为gelu
self.patch_embed = embed_layer(img_size,patch_size,in_channel,embed_dim,norm_layer)
num_patches = self.patch_embed.grid_size
self.cls_token = torch.nn.Parameter(torch.zeros(1,1,embed_dim)) #可训练参数(batch,1,embed_dim)
self.dist_token = torch.nn.Parameter(torch.zeros(1,1,embed_dim)) if distilled else None #知识蒸馏
self.pos_embed = torch.nn.Parameter(torch.zeros(1,num_patches+self.num_tokens,embed_dim))#(batch,197,768)
self.pos_drop = torch.nn.Dropout(p=drop_ratio)#position后的Dropout
dpr = [x.item() for x in torch.linspace(0,drop_path_ratio,depth)]#创建depth个递增的dpr
self.blocks = torch.nn.Sequential(*[
Block(embed_dim,num_heads,mlp_ratio,qkv_bias,qk_scale,drop_ratio,attn_drop_ratio,
dpr[i],norm_layer=norm_layer,act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
#representation layer
if representation_size and not distilled:#是否使用representation
self.has_logits = True
self.num_features = representation_size
self.pre_logits = torch.nn.Sequential(OrderedDict([
('fc',torch.nn.Linear(embed_dim,representation_size)),
('act',torch.nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = torch.nn.Identity()
#classifier heads
self.head = torch.nn.Linear(self.num_features,num_classes) if num_classes > 0 else torch.nn.Identity()#linear
self.head_dist = None
if distilled:
self.head_dist = torch.nn.Linear(self.embed_dim,self.num_classes) if num_classes > 0 else torch.nn.Identity()
#weight init
torch.nn.init.trunc_normal_(self.pos_embed,std=0.02)
if self.dist_token is not None:
torch.nn.init.trunc_normal_(self.dist_token,std=0.02)
torch.nn.init.trunc_normal_(self.cls_token,std = 0.02)
self.apply(_init_vit_weights)
def forward_features(self,x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0],-1,-1)
if self.dist_token is None:
x = torch.cat((cls_token,x),dim=1)
else:
x = torch.cat((cls_token,self.dist_token.expand(x.shape[0],-1,-1),x),dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:,0])
else:
return x[:,0],x[:,1]
def forward(self,x):
x = self.forward_features(x)
if self.head_dist is not None:
x,x_dist = self.head(x[0]),self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
return x,x_dist
else:
return (x+x_dist) / 2
else:
x = self.head(x)
return x
def _init_vit_weights(m):
if isinstance(m,torch.nn.Linear):
torch.nn.init.trunc_normal_(m.weight,std=.01)
if m.bias is not None:
torch.nn.init.zeros_(m.bias)
elif isinstance(m,torch.nn.Conv2d):
torch.nn.init.kaiming_normal(m.weight,mode = 'fan_out')
if m.bias is not None:
torch.nn.init.zeros_(m.bias)
elif isinstance(m,torch.nn.LayerNorm):
torch.nn.init.zeros_(m.bias)
torch.nn.init.ones_(m.weight)
def vit_base_patch16_224(num_classes: int = 1000):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f
"""
model = VisionTransformer(img_size = 13, #输入数据大小
patch_size = 1, #每个token大小
in_channel = 1024, #输入数据通道
num_classes = 125, #类别
embed_dim = 768, #token维度
depth = 12, #encoder重复次数
num_heads = 12, #多头注意力机制
mlp_ratio = 4.0,#mlp隐藏层倍数
qkv_bias = True, #查询QKV时是否使用偏置
qk_scale = None, #自定义缩放因子
representation_size = None, #是否使用representation
distilled = False, #是否知识蒸馏
drop_ratio = 0., #dropout比例
attn_drop_ratio = 0., #attention中dropout比例
drop_path_ratio = 0., #encoder中dropout比例
embed_layer = PatchEmbed, #patchembed
norm_layer = None, #归一化
act_layer = None)
return model
if __name__ == '__main__':
model = vit_base_patch16_224()
x = torch.randn(400,1024,13)
y = model(x)
print(y.shape)
🌜 总结 🌛
感觉这个模型应该是我复现过的所有模型中最大的一个了,而且最后感觉使用VIT去训练一维信号不如CNN。。。。因为一方面这个方面本身就是为了图片分类而创造的Transformer模型,另一方面他性能好很大一部分原因是因为使用了Image-Net上预训练得出的权重,而我们如果使用他来训练一维模型的话那些预训练的参数指定是用不了的。。。。
见仁见智吧这个问题,有写的不好的地方我们可以一起探讨。
最近好像还有个模型是使用ResNet进行特征提取,然后后面接VIT模型进行后续训练,感觉那个应该对于一维信号或许好使,找个时间可以实现以下试试看。




![腾讯云函数部署环境[使用函数URL]](https://i-blog.csdnimg.cn/direct/18f2ce17c76542a4aea985437ffdde17.png)